
He decidido publicar una serie de posts los Miércoles acerca de diferentes tecnologías. Así que aquí va el primero.
Hoy empezaré hablado de la multiplexación por división en el tiempo y en...
Bienvenidos a Los Miércoles de Tecnología
He decidido publicar una serie de posts los Miércoles acerca de diferentes tecnologías. Así que aquí va el primero.
Hoy empezaré hablado de la multiplexación por división en el tiempo y en posts siguientes hablaré sobre la estructura de la trama E1 que ha sido durante muchos años - y en algunos entornos aún lo sigue siendo - la estructura básica para las telecomunicaciones de voz y datos.
¿ Qué es la multiplexación por división en el tiempo o TDM (Time Division Multiplexing ?
Decimos que una señal está multiplexada en el tiempo cuando asignamos a cada uno de los flujos de información que lo componen un intervalo de tiempo. Dentro del intervalo asignado, la fuente puede insertar tráfico en el flujo combinado, fuera de este intervalo no puede hacerlo.
Como resultado, tenemos un flujo combinado o multiplexado cuya velocidad es, a grandes rasgos, la suma de velocidades de cada uno de los flujos combinados.
Esta última afirmación es estrictamente cierta si todos los flujos tuvieran exactamente la misma velocidad. Cuando estos flujos tiene una velocidad o reloj diferentes, no se pueden combinar directamente y necesitamos disponer de bits de relleno para poder ajustar estas variaciones.
En la figura siguiente vemos un ejemplo donde multiplexamos 3 flujos de 64Kbit/s de velocidad cada uno resultando en un flujo combinado teórico de 3 x 64 = 192 Kbit/s
En la figura siguiente vemos un ejemplo donde multiplexamos 3 flujos de 64Kbit/s de velocidad cada uno resultando en un flujo combinado teórico de 3 x 64 = 192 Kbit/s

64K - La codificación de la voz y el criterio de Nyquist
El criterio de Nyquist nos indica que si queremos poder digitalizar o codificar una señal analógica sin pérdida de calidad y/o información, debemos hacerlo, es decir tomar muestras, a una velocidad igual o superior a la frecuencia máxima de dicha señal.
Si hablamos de telefonía, la voz humana se encuentra en el espectro de 300 a 3400Hz. Por tanto, asumiendo una señal de unos 4KHz, tenemos que codificarla a una velocidad doble, es decir, de 8KHz o lo que es lo mismo, 8000 muestras por segundo.
¿En cuántos segmentos o trozos descomponemos nuestra señal analógica? Cuántos más mejor ya que menor será el error o diferencia entre la señal analógica original y la digital 'reconstruida'. En la codificación de voz PCM (Pulse Code Modulation) que sigue el estándar ITU G711 usamos 256 niveles y por tanto necesitamos 8 bits (del 00000000 al 11111111) para codificar estos 256 niveles.
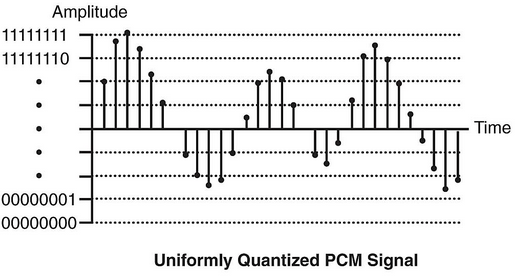
Si debemos usar 8 bits 8000 veces por segundo, tenemos una velocidad de datos de una señal PCM de 8bits x 8Kbit/s = 64 Kbit/s. Por tanto, necesitamos 64Kbit/s para codificar una señal de telefonía.
Este valor de 64K es la unidad básica de información sobre la que se montarán estructuras superiores como el E1 (2048K), E2 (8M), E3(34M) o las jerarquías SDH (STM-1 155Mbps).
Posteriormente a la codificación G.711 salieron muchos otros algoritmos de compresión en los que se basan todos los sistemas de voz sobre IP (VoIP) y que permiten reducir en gran medida esta velocidad. Un ejemplo es el algoritmo ADPCM (Adaptive Differential Pulse Code Modulation) recogido en la norma G.726 y que permite codificar la misma señal a 16, 24, 32 o 40 Kbit/s en vez de los 64 Kbit/s ya que necesita menos bits puesto que codifica no el valor de la señal en el tiempo del muestreo sino la diferencia entre una muestra y la anterior, valor que siempre es mucho menor que el valor de la señal en sí y por tanto podemos tener la misma resolución o precisión con un número menor de bits.
No hay comentarios:
Publicar un comentario